Hello All,
As I mentioned in the last middleware working group meeting, the iRobot team would like to propose a change to how ROS2 handles incoming events.
We believe that rather than using user level waitsets, that an executor event queue design will allow events to propagate faster. When the executor thread is waiting on events to arrive, it simply blocks allowing the CPU to perform other work. When awakened, the events are processed in the order they are received. Each event contains the a type enumeration and a unique handle to process the event.

IMPLEMENTATION DETAILS :
Use a push interface with a queue to signal events to the executor.
This allows the custom middleware event handlers to notify the executor immediately via a callback pointer. The provided event type and handle allows access to the resource without searching. This callback datatype is (currently) part of the rcutils and does not require the executor data types to pollute the middleware implementation. This design removes the overhead of adding, polling, and checking the waitsets for subcriptions, clients and services when checking for new work.
Slower list maintenance is only performed when the resource is created or deleted.
Currently there is a single queue per executor with events presented to the user in received order with no implied priority of event types.
Executor blocks waiting on Queued Events
In this design the executor blocks waiting on a queue event. When signaled, the events are removed and processed. This will work using spin(), spin_some(), or spin_once() if needed by blocking or processing the entire queue, or only processing some of the items. This blocking method will allow the thread to wait without consuming CPU until user work is ready to be executed.
Offload timers to its own thread
The current design requires timer maintenance to be performed during the rcl wait operations. In this design we propose to offload the timer operations to its own thread and signal the executor of timer expiry using the event queue. An alternative interface could also execute the callback directly if the user specified it as such, however thread safe practices would apply to the user in that case.
Another advantage of timer offload is that the underlying operating system timer facilities can can be used to better manage the pool. Since these operate closer to the operating system scheduler, more accurate results could be obtained, especially for longer duration intervals.
DESCRIPTION OF TESTS :
We implemented a quick proof of concept for this design where we compared:
- Default ROS2 master
- ROS2 with new event queue method
- FastDDS without ROS2
Tests were conducted on a RPi 1 (single core, ~700Mhz) using our performance framework and the Sierra-Nevada Topology.
The implementations use the static single threaded executor, running all nodes as a single process.
The intra-process IPC (rclcpp) has been disabled to force all messages through the full DDS interface.
We use eProsima’s FastDDS, and rmw_fastrtps_cpp as middleware in these tests.
There are 3 test results shown :
-
“Default ROS2” - This is the latest master branch of ROS2 without any changes.
-
“ROS2 w/Event Queue” - This is default ROS2, with a modification to use an event queue for subscriptions, clients, and services. Although, we do not exercise the client or service facilities in our performance framework. As described above, the executor blocks waiting on an event, with subscription callback assignment performed at create time. The timer offload is not implemented for these measurements so that we can gauge the impact of each feature change. Our performance framework still uses ROS2 timers, and should show load from timer maintenance.
-
“FastDDS w/No ROS2” - This is an implementation of our test framework without ROS2 using eProsimas FastDDS. This test allows us to see what the load and latency is without the ROS2 overhead. The message sizes and production rates are exactly the same as the Sierra-Nevada topology used for the other tests. Processing is performed immediately when the messages arrive.
PROOF OF CONCEPTS :

CPU Load for the default ROS2 is consistent with our previous experience.
With an event queue processing on subscriptions the load is reduced by 25%.
We believe that offloading the timers to a separate timer manager thread will reduce the load even more.
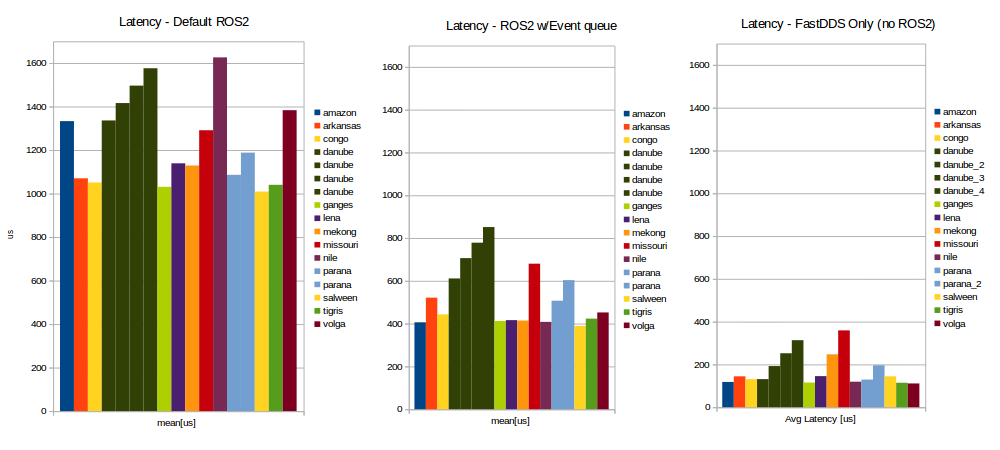
Message latency measurement is the interval between when the message is created, and when it is received. The default ROS2 has a baseline of just over 1ms. When using this new Event Queue the latency is down to 400us (reduction between 2 and 4 times). The direct FastDDS implementation shows that the ROS2 overhead accounts for just under 300us of time per event.
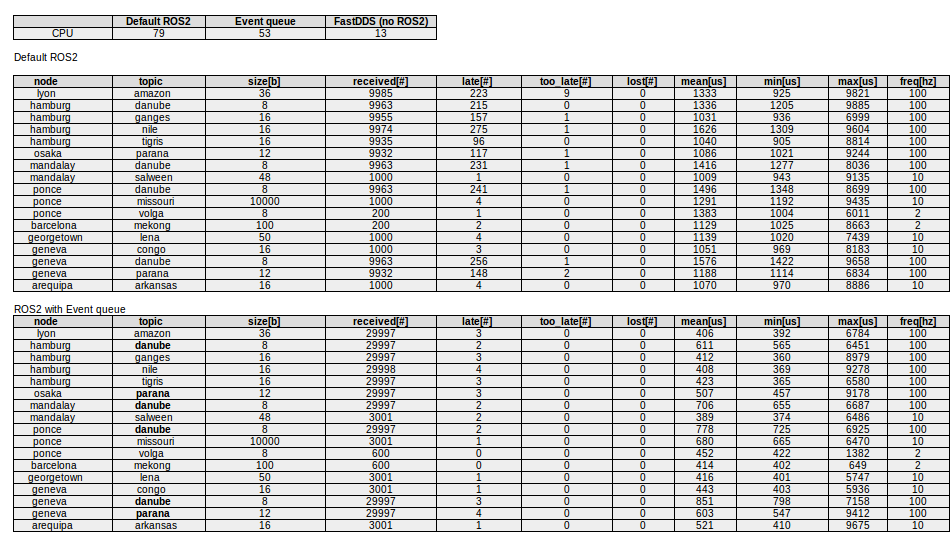
Raw Data :
CONCLUSION :
We understand that this is a very different design that what is currently implemented, but we believe that this will improve the flow of events through the stack so that the CPU bandwidth can be focused on user facing work.
What we have done here is the result of a simple prototype to prove out an architecturally sound event propagation method with as few modifications as possible. If this is acceptable to the group, we can implement a more formal approach for detailed review.
As always we look forward to the everyone’s thoughts,
Thank You,
-Lenny
