We get often asked about relative performances of Zenoh when compared to other technologies. The good news, is that a team of researcher from the National Taiwan University (NTU) has contributed a blog that compares the performances of Zenoh with MQTT, Kafka and DDS.
The performance evaluation shows that zenoh has best overall performances with a peak throughput of 67Gbps and latency as low as 5usec.
… and if I may I’d add, the simplest code to write too, especially when using the Rust API
As for me the tests looks a bit unfair.
Authors used QoS reliability settings RELIABLE for DDS.
It will give a big penalty in throughput tests. Since if one message will be lost, DDS will try to send it over and over and throughput will degrade. Usually for max throughput tests uses best effort settings for QoS reliability.
Overall DDS on par or very close with Zenoh on graphs. And even doing better in latency tests.
Also in tests was considered only data transmission over the network i.e. Ethernet interface.
But how about tests when nodes on the same ECU?
CycloneDDS has pretty good integration with iceoryx for shared memory transport.
It would nice to see comparison for transferring data on the same ECU as well.
Agreed. Its not about what the most optimal metrics are possible from it, but what you would largely be using in your practical system. While I have some communication topics over Best Effort, the vast majority are Reliable, so I care about that most. I think that’s actually a more useful comparison.
I don’t like disingenuous comparisons that are designed to show things in only their most optimal lights but aren’t the most frequent mode of operation for robotics.
Edit: Nav2 and mobile robotics centric. Can’t speak to every application in robotics, but there’s alot of data we need to have reliably more than “as easy”.
@smac There are subtle difference between the vast majority topics and most “heavy” topics which are dominate in in total data throughput.
It practice for camera images and point clouds usually uses best effort QoS settings for the sake of low latency and maximum throughput.
From algorithm and decision making nodes perspective it will be more beneficial to drop one camera image rather then delay whole computer vision pipeline waiting while lost image will be re-transmitted. Or even worse re-transmission of camera images will cause messages lost and bigger delays on other more important topics with reliable QoS settings due to the limited throughput and bandwidth capability.
I’m not arguing against QoS or saying there aren’t uses of Best Effort (we use it often in situations like you describe, mostly surrounding sensor data or costmaps for visualization). Only that I think benchmarks, if we have to choose only one QoS profile, should be Reliable since that gives me a good understanding of which is better for the largest portions of robotic systems (and knowing that Best Effort will be better, versus if we only have Best Effort, I have no idea ‘how much worse’ Reliable would be)
Hello @MichaelOrlov, as you can read on the blog, the authors correctly used reliable communication with blocking congestion control for Zenoh. This is equivalent to the behaviour you have in DDS with RELIABLE Reliability and KEEP_ALL history on both the reader and the writer side. As you may know, this is the only DDS QoS configuration that ensures that samples may not be discarded – if the History QoS is set to KEEP_LAST, DDS promises to deliver reliably the last N samples, where N depends on the history depth settings.
Thus, the settings used by the NTU team are perfectly fine and fair.
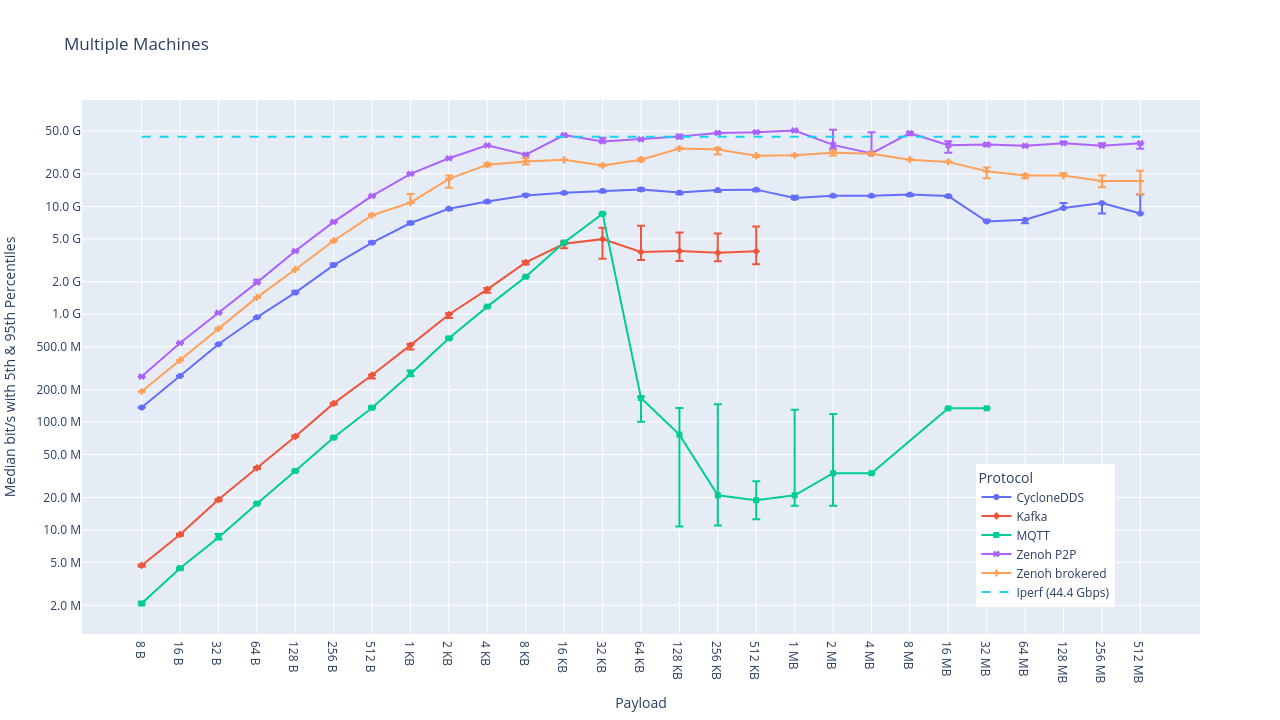
Concerning the results, please look carefully at the Y axis (see https://zenoh.io/img/20230321-performance-comparison/plots/multi/bit_per_second.png), since what may seem a small difference may be easily tens of Gbps. For instance across the network you’ll notice that for 16KBytes Zenoh is at 50Gbps while Cyclone is around 14Gpbs. The line look close, but again, you need to read carefully the scale.
Finally, the latency is 10usec for Zenoh peer-to-peer (only 2us more than DDS). Yet, you should keep in mind that Zenoh are able to route over an arbitrary mesh as opposed to just a clique (as DDS). That said, for Zenoh-Pico, which does not have this additional feature, its latency is 5usec, which is the lowest overall.
Finally, NTU was interested in measuring the protocol efficiency and going through ICEOryx for Cyclone DDS or using Zenoh zero-copy support would kind of defeat the purpose.
Hello @smac, I’ll summarise below the results presented in the blog. I’ve noticed that a few readers overlooked the Y axis and did not realise that the difference between one tick and another could be as much as 10Gpbs. The network is 100Gbps, that makes a big difference.
In summary as reported in the image below, which shows the throughput across the network, Zenoh (peer-to-peer) delivers by far the highest throughput and in this tests it was found to deliver over 3x higher throughput than DDS, and over 10x higher throughput than Kafka and MQTT.
Specifically, for 16KB payload Zenoh has 50Gbps throughput vs 14Gbps of DDS, and ~5Gbps for MQTT and Kafka.
Latency, numbers are reported below. Across the network zenoh consistently delivers the lowest latency, while on loopback is very close two DDS, with Zenoh-Pico being a little bit better.
For those of you that are not familiar with Zenoh-PIco, this implementation targets MCUs and does not support mesh-routing, this is mostly the reason for the lower latency.
Hello @Caleb_Eastman, Zenoh supports best-effort and reliable communication and provides and orthogonal mechanism to control congestion. As a consequence of a theoretical limitation on the theory of distributed systems, on an asynchronous network ensuring reliability requires to either give away progress or to have infinite amount of memory.
As we don’t have today and won’t have anytime soon infinite amount of memory, to escape from this impasse, usually reliability gives up progress. Yet, in Zenoh we think that this is not always a good compromise, under congestion you may want to drop samples… Or at least allow for that to avoid loosing progress.
Long story short, in zenoh, you can control along with the reliability the congestion control algorithm Today we have two, one that may drops samples to help resolving the congestion and another that won’t and thus impact progress.
In DDS you can get similar behaviour by playing with RELIABILITY and HISTORY QoS, although that requires to have the right settings on the two side of the endpoints.
Concerning IceOryx, as it stands Zenoh has its own Zero copy mechanism. Thus you may wonder why?
There are two main motivations:
Zenoh is written in Rust and we don’t want dependencies to C/C++ codes on our core, unless we can’t really do w/o. This rule is mostly about avoiding to introduce security holes via C/C++ libraries. FYI, we don’t even use OpenSSL we use RUST TLS…
Zenoh already does pub/sub and thus we leverage our current pub/sub to implement Zero-Copy via distributed shared memory and for Rust APIs that is integrated with the ownership mechanism.
We do have some news, let’s say that short term (~May 2023) we’ll have a solution that will look like a Zenoh RMW, with the advantage of being able to properly manage outbound traffic, both in therm of what goes how as well as in terms of rate limiting etc. This latter point is something that was quite useful for the Indy Autonomous Challenge*.
That said, we would like to see a Zenoh RMW, and from the requests we see on our Discord Channel it seems that this is what the community would also like to see.
We are happy to work on this, but can’t do if all alone. Happy to resume discussions from where we left.
– kydos
(*) For those thinking that the TimeBasedFilter provided by DDS can solve the problem, the reality is that that filtering happens on the receiving side, thus not limiting any traffic on the network.
@kydos thank you for sharing information, good work (including NTU team )
I would like to ask technical comment to the result between Zenoh brokered and Cyclone DDS case, which tells us that Zenoh brokered is better than Cyclone DDS.
I was expecting basically P2P(in this case Cyclone DDS data-plane) would be better performance compared to Brokered(or proxied) configuration. I think this is likely so, because the basic architecture is different. As network topology, brokered packets need to take twice as long.
Could you describe or share your thoughts against above expectation turned out wrong in technical aspect? It does not have to be precise, just ideas or zenoh features you want to point out would be really appreciated.
btw I checked zenoh almost a couple of years ago, and i think one of the key feature could be related to this result is minimize the packet overhead (if i am not mistaken, down to 4 bytes?), do you think this is also related to this result?
I believe that you are the best person to ask this question
thank you very much in advance.
If you consider the latency, then adding the router in between, has an effect end-to-end. However, for throughput the story is different. A publisher/router/subscriber are a software pipeline, thus as far as each of the stages are able to sustain the same throughput, you may increase the latency but the impact on the end-to-end throughput should be minor. This is precisely what you see on that performance diagram, the router in the middle is sufficiently efficient not to majorly impact the throughput (the difference that exist comes from the fact that the router is doing more work than the pub or the sub as he is both receiving and sending). That said if you look at the resulting latency that is more than doubled since you have one extra hop and sending a receiving on the same machine thus some extra context switching.
I hope this clarifies why the number are not actually surprising.
With respect to wire-overhead, Zenoh has indeed a very small minimal wire-overhead, which is around 5 bytes. But I guess that in this benchmark the big difference is made by the fact that the protocol is simpler to parse than DDSI, smaller in size thus more cache friendly.
Hope this answers your question. Please don’t hesitate to follow-up if some of my points were not clear.


{kind=link}