Hi all,
I’m Alberto, from iRobot.
As you may know, my colleague Juan and I gave a presentation at ROSCon about using ROS 2 in consumer robotics application.
If you missed it, you can find it here iRobot-ROSCON.pdf | DocDroid
The purpose of our talk was to discuss about a performance gap in ROS 2 that was preventing it from being effectively used on a particular class of platforms:
we thought that Linux-based, low cost, embedded platforms (as RaspberryPi) were not taken enough into consideration.
During our talk we highlighted the most relevant problems of the current (Dashing) release and we suggested some improvements.
All the experiments presented in the talk or in this blog post have been performed using our open-source performance evaluation framework: it’s a very simple framework that measures some fundamental performance metrics; its peculiarity is that it allows to simulate any type of arbitrarily complex ROS 2 system through a JSON file.
You can find it here GitHub - irobot-ros/ros2-performance: Framework to evaluate peformance of ROS 2.
We want to thank all of you for the interest you showed in the problems that we presented and we are extremely happy to see all the work that is going on to address these issues.
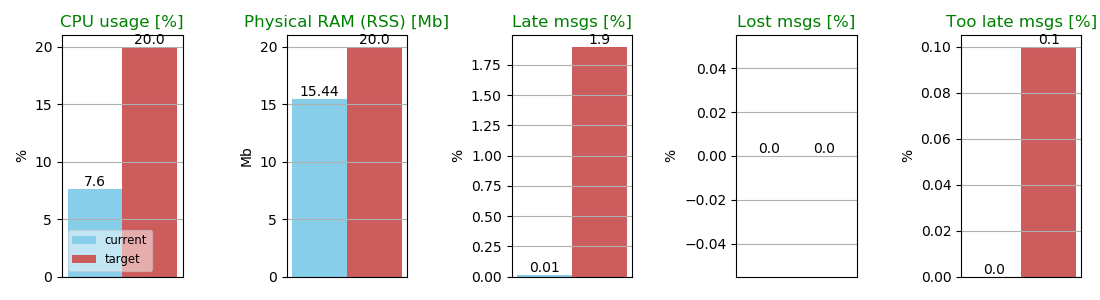
First of all, we can have a look at the default performance of the current ROS 2 master.

The performance are already a lot better than what we measured for Dashing, in particular the CPU usage and the latency improved and we have a reduction of ~40 Mb of RAM. We have no more “too late” or “lost” messages (we are in a single process scenario, so this is highly desirable!)
However, what is really interesting is all the work that is currently going on and will be part of the next releases
-
CycloneDDS
Refactor of the serialization procedure: this made the code cleaner and it reduced latency and CPU usage, especially for big messages.
Rework serialization by rotu · Pull Request #42 · ros2/rmw_cyclonedds · GitHub (results here)
This has been recently merged to master.
Improving the deserialization procedure will be the next step and many more features are coming since this DDS has been added to the list of ROS 2 stable sources. -
FastRTPS
Substantial improvements on the memory side: before most of the memory allocation was happening at startup to target real-time use cases, while now the default behavior will be more memory efficient in scenario where real-time constraints are not present.
The RAM usage in our benchmark goes from 116 Mb to 33 Mb.
Part of this is already available in master, while other works will be ready for the next Eloquent relase.
GitHub - eProsima/Fast-DDS: The most complete DDS - Proven: Plenty of success cases. Looking for commercial support? Contact info@eprosima.com
-
RMW Iceoryx
A new RMW, completely based on a shared memory layer in order to ensure best performances for inter-process communication.
This is already available and it’s receiving a lot of interst and support.
GitHub - ros2/rmw_iceoryx: rmw implementation for iceoryx -
Static Executor
A first step towards the refactor of executors inrclcpp. This new executor performs the best when most of the nodes are already available at startup, but is still able to recognize new publisher/subscriptions.
Unfortunately, it is not updated to the current master, so I haven’t been able to test it extensively, but the CPU usage looks definitely better!
It’s targeting the next ROS 2 release, Foxy.
GitHub - nobleo/static_executor: Library that adds alternative(s) to the default executor in ROS2
SingleThreadedExecutor creates a high CPU overhead in ROS 2

With all this work going on, I think that we can say that if Dashing and Eloquent were the releases that added to ROS 2 most of the required features, with the next release, Foxy, the ROS 2 performances will get a big improvement!
Let’s keep going in this direction, to make ROS 2 a success!