Hi Alberto,
As you said, Fast RTPS and rmw_fastrtps default settings are designed for real-time behaviour:
1.- Static allocations: We allocate some memory at startup to avoid dynamic allocations. While this is good for many applications, it is not if you are looking for minimum memory usage.
2.- Async Publishing: The user thread is not publishing directly the message but copies the data to a buffer, and a middleware thread does the actual publication. This is good for real-time determinism as the user thread returns immediately. But is not good if you are looking for minimum latency.
Also, the Fast RTPS for dashing didn’t count with an intra-process mechanism.
Therefore in your initial comparison, you were comparing:
- Fast RTPS: Static Allocations + Async Pub + Loopback (Dashing)
- Cyclone DDS: Dynamic Allocations + Sync Pub + Intraprocess (Latest)
But, if you setup Fast RTPS with the recommended settings for this case and use the latest version, you get:

This experiment includes the whitelist mechanism you recommended in your presentation (10 mb less of memory usage). A lot better, and matching your requirements.
The documentation to setup the rmw of fast RTPS is in the readme of the rmw: GitHub - ros2/rmw_fastrtps: Implementation of the ROS Middleware (rmw) Interface using eProsima's Fast RTPS.
Also is worth to comment ROS2 is creating a DDS participant per publication or subscription, leading to a lot of participants. That is not the recommended use of DDS, and in this case leads to a lot of participants. For the next ROS2 release this behaviour is going to be fixed:
We did an experiment using your framework with an equivalent topology, but just a single DDS participant. In that case:
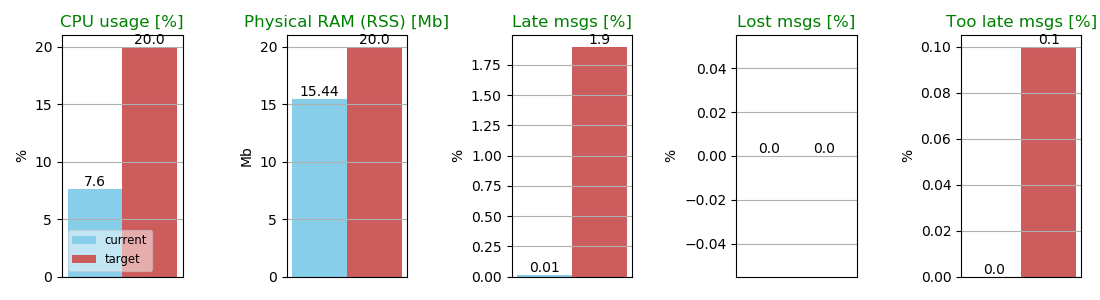
With 1-to-1 mapping, both the memory and the CPU usage improve a lot, as it is the recommended way to use DDS.
How to Reproduce the results:
Also, to easily reproduce these results and the different experiments, we created a complete Rosject:
https://rds.theconstructsim.com/l/f196e4b/
Important Note: iRobot scenario uses a Raspberry Pi with raspbian. The rosject creates a cloud instance using linux, and the memory page size is bigger than in a raspberry PI, so the memory measures are higher for any configuration, but it is useful to understand the differences.
As conclusion, ROS2 with Fast RTPS is highly configurable, making ROS2 fast and reliable for very different cases, and for Foxy we will focus on performance, so as you predict, it will be even better.
More Resources:
For a how-to on how to change the basics:
GitHub - ros2/rmw_fastrtps: Implementation of the ROS Middleware (rmw) Interface using eProsima's Fast RTPS. (readme)
And for detailed documentation of all the available options, see:
https://fast-rtps.docs.eprosima.com/en/latest/xmlprofiles.html#